The Fear of Unicode/UTF-8
As a programmer - especially as a C/C++ programmer - you might be reluctant to embrace the Unicode beast. You vaguely know that wchar.h contains various functions to handle the dirty things, but it does not make things clearer. In Java, programmers are using String without troubles, until they want to convert them from/to arrays of bytes (hey, how Java is supposed to handle supplemental characters ?)
Unicode is very simple in its essence, even if you can make things unreasonably complex (have you ever decomposed an Unicode character ?): this is basically the extension of the ASCII concept (assigning a number to a character) to fit more characters.
The Simplicity Behind The Complexity
Yes, Unicode is rather simple if you keep things simple.
Let’s begin with some concepts:
-
Unicode: a consortium aimed to standardize all possible characters in use on Earth (even the most improbable languages - but this does not include Klingon), such as latin characters, Chinese, Arabic, etc., and assign them a number. Numbers from 0 to 127 are the standard 7-bit ASCII, and code points above are non-ascii characters, obviously (the first range assigned above being latin letters with accents)
-
UTF-8: a way to encode an Unicode character code into a sequence of bytes ; 7-bit ASCII is encoded “as is”, using 7-bit ASCII (ie. the code point for the letter “A”, which is the letter 65 in the Unicode world, is encoded into the ASCII byte “A”, which is also 65 in the ASCII world), and the rest is using a sequence of bytes in the range (in hex)
80..FD(FEandFFare never used, which is pretty cool, because this greatly helps making the difference between an UTF-8 stream and other encodings) -
UCS-2: encoding of Unicode points as 16-bit wide characters - basically, an array of
uint16_t- note that you may only encode Unicode points from 0 to 65535 (something which is called the “Basic Multilingual Plane”, or BMP). This is generally used internally only - most people won’t store or send raw arrays ofuint16_t. You may have two flavors: UCS-2BE (big-endian flavor), or UCS-2LE (little-endian flavor), and a common trick to detect the endianness is to put a zero-width no-break space (sometimes called byte order mark) as first invisible character in a text stream, whose code point isFEFF. The “reverse” code pointFFFEis invalid in Unicode, and should never appear anywhere. Oh, did I tell you thatFEandFFnever appear in an UTF-8 stream previously ? If you use the byte order mark, you’ll never confuse an UCS stream with an UTF-8 one. -
UCS-4: encoding of Unicode points as 32-bit wide characters - basically, an array of
uint32_t. You also have two flavors: UCS-4BE (big-endian flavor), or UCS-4LE (little-endian flavor), and the byte-order-mark trick is also used in many places. -
UTF-16: encoding of Unicode points as 16-bit wide characters (like UCS-2), except that Unicode points beyond the Basic Multilingual Plane are encoded as two 16-bit characters in the surrogate range. This is a bit wicked: we are encoding a character using two characters, and each of them are encoded as 16-bit characters. You can treat an UTF-16 stream as a regular UCS-2 stream - in this case, code points beyond the Basic Multilingual Plane will be seen as a pair of unknown-class characters (surrogates).
-
UTF-32: this is actually the synonym for UCS-4 (and is in my opinion an confusing naming: this is not a variable length encoding). Oh, and you are not supposed to have surrogates (used for UTF-16, see above) inside an UCS-4/UTF-32 stream.
More Precisely, What About UTF-8 ?
Let’s have a look as UTF-8, which is generally the preferred encoding for storing and sending data (most RFC are using UTF-8 as default encoding nowadays).
The good news is that 7-bit ASCII is a subset of UTF-8: nothing will change on this side.
For the rest, UTF-8 is a very simple and smart encoding (Ken Thompson is behind this fine piece of work), and decoding it is not really hard.
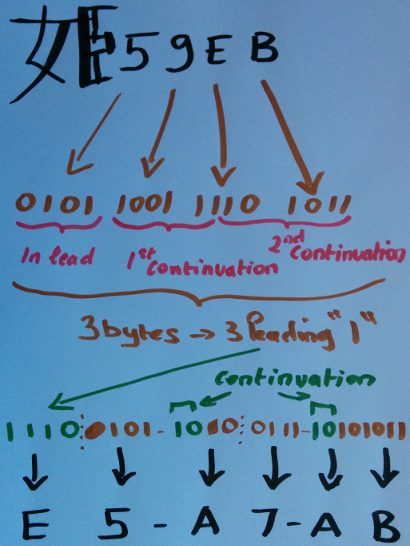
If a character outside the 7-bit range is used, UTF-8 will encode it as a byte sequence. For example, the “é” letter (latin letter e with acute accent), which is in the Unicode world the point E9 (in hexadecimal - that is, 233 in decimal), will be encoded as bytes C3 and A9 (C3 A9) (which is displayed as “é” - something you’ll learn to recognize and which generally is a sign of UTF-8 not being recognized by a client). The “姫” Chinese character (“princess”), which is in the Unicode world the point 59EB (23019 in decimal), will be encoded as E5 A7 AB (displayed as “姫” if your display client or browser is having troubles recognizing it).
To understand UTF-8, you just need to know one thing: for a given byte, visualize its 8 bits, and count the number of leading “1” (ie. the number of “1” before the first “0”). This is the only information you need to know whether this byte is a single 7-bit ASCII character, the beginning of an UTF-8 sequence, or an intermediate byte within an UTF-8 sequence. Oh, and if the byte is the beginning of a sequence, you also know how long it is: its length is precisely the number of leading “1”. Isn’t that magic ?
Yep, this is it.
Basically,
- no leading “1”: 7-bit ASCII (
0..7F) - one leading “1”: in the middle of a sequence
- two or more leading “1”: a sequence whose length is the number of leading “1”
This is an extremely good property of UTF-8: you can easily cut an UTF-8 string/skip characters/count characters without bothering about actual code points. Only bother about leading “1”’s.
Oh, by the way: did you know that the number of leading “1” could be computed without using a loop ? Take a look at the Hacker’s Delight recipes (do not hesitate to buy the book, it is worth it, and recipes are presented with their mathematical explanation - there is no pure magic out there)
Here’s the trick: (this is the number of leading zeros, but you probably have an idea on how to use this function to compute the number of leading ones)
/* Hacker's delight number of leading zeros. */
static unsigned int nlz8(unsigned char x) {
unsigned int b = 0;
if (x & 0xf0) {
x >>= 4;
} else {
b += 4;
}
if (x & 0x0c) {
x >>= 2;
} else {
b += 2;
}
if (! (x & 0x02) ) {
b++;
}
return b;
}
We know how to recognize UTF-8 sequences, and we even know how to get their length. How to encode Unicode points ?
Encoding is extremely simple. It could not be simpler, actually: visualize your Unicode point as a stream of bits (starting from the leading “1”). You’ll encode them in the remaining space, in the first leading character, and in the remaining sequence. The remaining space within sequence bytes is the space after the leading “1” and the “0” delimiter.
For example, if the leading byte defines a 4-byte sequence, then it will start with four “1”, and a “0” delimiter. Three bits remains available for encoding (the first three bits of the Unicode point number, starting from the leading “1”, will be encoded there). Continuing characters (in sequence) have a leading “1” followed by the “0” delimiter: six bits are available for encoding.
Let’s go back to the “姫” Chinese character. This character is 59EB in the Unicode charts ; here’s how it is encoded as E5 A7 AB (and sorry for my lame Chinese writing skills!):
An Exercise For You!
As an exercise, you can now easily rewrite the getwchar() function in an UTF-8 environment (locale).
Here’s my try (do not cheat! look at this solution after you tried!):
#include <stdio.h>
#include <stdlib.h>
#define UTF8_ERROR ( (int) (-2) )
/* Hacker's delight number of leading zeros. */
static unsigned int nlz8(unsigned char x) {
unsigned int b = 0;
if (x & 0xf0) {
x >>= 4;
} else {
b += 4;
}
if (x & 0x0c) {
x >>= 2;
} else {
b += 2;
}
if (! (x & 0x02) ) {
b++;
}
return b;
}
/* Length of an UTF-8 sequence. */
static size_t utf8_length(const char lead) {
const unsigned char f = (unsigned char) lead;
return nlz8(~f);
}
/* Equivalent to getwchar() on an UTF-8 locale. */
static int utf8_getchar() {
const int c = getchar();
const size_t len = utf8_length(c);
if (c < 0) { /* EOF */
return EOF;
} else if (len == 1) { /* ASCII */
return UTF8_ERROR;
} else if (len == 0) { /* Error (in-sequence) */
return c;
} else { /* UTF-8 */
unsigned int uc = c & ( (1 << (7 - len)) - 1 );
size_t i;
for(i = 0 ; i + 1 < len ; i++) {
const int c = getchar();
/* not EOF, and second bit shall always be cleared */
if (c != -1 && ( c >> 6 ) == 0x2) {
uc <<= 6;
uc |= (c & 0x3f);
} else if (c == -1) {
return EOF;
} else {
return UTF8_ERROR;
}
}
return (int) uc;
}
}
int main(int argc, char* argv[]) {
for(;;) {
const int c = utf8_getchar();
if (c == EOF) {
break;
} else if (c == UTF8_ERROR) {
fprintf(stderr, "* UTF-8 error\n");
} else {
printf("unicode character 0x%04x\n", c);
}
}
return EXIT_SUCCESS;
}
Note that the above code can be improved a little bit, by unrolling the for() loop, and using few switch.
TL;DR: Do not worry, and embrace UTF-8 and the Unicode world.